
 加密货币 三大交易所
加密货币 三大交易所本文结构
1.什么是编译器?
2.关于LLVM之父Chris Lattner
什么是XLA和MLIR
LLVM是什么?
什么是Clang
Clang和LLVM的关系
3.关于Modular
Modular——人工智能引擎
关于谷歌的TPU
关于深度学习和可编程性
实际构建引擎的过程中存在有哪些技术挑战?
4.关于创业,和工程团队建设、AI的未来
一、什么是编译器?
编译器(Compiler),是一种将高级编程语言翻译成计算机可执行代码的软件工具,编译器将程序员编写的源代码转换成计算机可以理解和执行的二进制指令,这些指令被打包成可执行文件或库,以便在计算机上运行程序。
编译器的主要工作流程是源代码(source code)→预处理器(preprocessor)→编译器(compiler)→目标代码(object code)→链接器(Linker)→可执行程序(executables)
再举个形象的例子:
老师:小朋友们,今天我们学习加法。
bla bla bla ……
小朋友们:老师,我们学会了。
老师:现在你们就是能读懂 1+1=?的编译器了
二、LLVM之父Chris Lattner
在讲Modular之前,我们先讲讲Chris Lattner的经历,他1978年出生在美国加利福尼亚州,在旧金山湾区长大,很年轻的时候就开始编程,之后他在UC Berkeley获得计算机科学学士学位,并在斯坦福大学(Stanford University)攻读博士学位,方向主要是编译器优化和自动并行化。
Chris Lattner在读博士学位期间主导开发了 LLVM,因为LLVM,获得了 2012 年 ACM软件系统奖(ACMSoftware System Award)。之后,Lattne被苹果聘用,在苹果公司负责了许多重要项目,包括Clang编译器前端、Swift(取代 Objective-C 的语言)编程语言的设计和开发,以及Xcode开发环境的改进。Swift语言因其简洁性和性能而受到广泛欢迎,并被开发者用于iOS、macOS和其他苹果平台的应用程序开发。
离开苹果公司后,Chris Lattner曾在特斯拉(Tesla)和谷歌(Google)等公司工作,并继续在编程语言和编译器技术领域发表研究论文和参与开源项目, 在谷歌负责领导 Tensorflow 基础架构团队,创建了 XLA和 MLIR。
这里我们解释一下什么是XLA和MLIR:
XLA(Accelerated Linear Algebra:加速线性代数)是一种针对特定领域的线性代数编译器,能够加快 TensorFlow 模型的运行速度,而且可能完全不需要更改源代码。它可以提高运行速度并改进内存用量。
MLIR(Multi-Level Intermediate Representation:多级中间表示)是一种编译器框架,它的设计优化了编译器,基本把编译器设计中的通用部分全部包揽,极大地方便了编译器的开发人员。
还有更重要的,LLVM是个啥?(以下摘自简书,原文见参考链接)
可以把LLVM理解为模块化、可重用的编译器以及工具链技术的集合。LLVM(其实是Low Level Virtue Machine的全称,但是它从来没被用做虚拟机)所以后面LLVM也不是首字母缩略词; 它是项目的全名。
然后我们继续,传统编译器架构长下面这样:
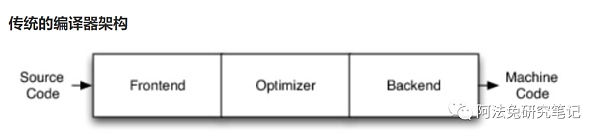
拆开来看的话,包括:
Frontend:前端(词法分析、语法分析、语义分析、生成中间代码)
Optimizer:优化器(中间代码优化)
Backend:后端(生成机器码)
而LLVM架构长这样

准确地形容的话,LLVM在编译器这块,进行了很多创新,比如说:
不同的前端后端使用统一的中间代码LLVM Intermediate Representation (LLVM IR)
如果需要支持一种新的编程语言,那么只需要实现一个新的前端
如果需要支持一种新的硬件设备,那么只需要实现一个新的后端
优化阶段是一个通用的阶段,它针对的是统一的LLVM IR,不论是支持新的编程语言,还是支持新的硬件设备,都不需要对优化阶段做修改
相比之下,GCC的前端和后端没分得太开,前端后端耦合在了一起。所以GCC为了支持一门新的语言,或者为了支持一个新的目标平台,就 变得特别困难
LLVM现在被作为实现各种静态和运行时编译语言的通用基础结构(GCC家族、Java、.NET、Python、Ruby、Scheme、Haskell、D等)
什么是Clang?
LLVM项目的一个子项目,基于LLVM架构的C/C++/Objective-C编译器前端。相比于GCC,Clang具有如下优点
编译速度快:在某些平台上,Clang的编译速度显著的快过GCC(Debug模式下编译OC速度比GGC快3倍)
占用内存小:Clang生成的AST所占用的内存是GCC的五分之一左右
模块化设计:Clang采用基于库的模块化设计,易于 IDE 集成及其他用途的重用
诊断信息可读性强:在编译过程中,Clang 创建并保留了大量详细的元数据 (metadata),有利于调试和错误报告
设计清晰简单,容易理解,易于扩展增强
Clang与LLVM关系

LLVM整体架构,前端用的是clang,广义的LLVM是指整个LLVM架构,一般狭义的LLVM指的是LLVM后端(包含代码优化和目标代码生成)。
源代码(c/c++)经过clang--> 中间代码(经过一系列的优化,优化用的是Pass) --> 机器码
参考资料:简书-Aug 12, 2018-深入浅出让你理解什么是LLVM
三、关于Modular
Modular——人工智能引擎
Chris Lattner对编译器和创业做Modular的思考有哪些?
Chris Lattner:"我创建Modular,不是拿着锤子找钉子,也不是为创新而创新,目前对OpenAI 这样的公司来说,少数员工需要花费大量时间手动编写 CUDA 内核。但是,针对人工智能编译器的优化,可以用编译器提高软件协作,扩大拥有不同技能和知识的人员的能力”
"编译器的最终形态,是希望能让用户不需要对硬件有太多了解,可以用非常简单的汇编代码来完成任何和解决问题,编译器的真正作用是,能用更高的抽象级别来进行表达。"
"英伟达推出的 FasterTransformer,能够带来巨大性能提升,因此,很多大模型公司和开发者都在使用FasterTransformer,但是,如果想在Transformer 领域进行创新,就会受到 FasterTransformer 的限制。"
也就是说,编译器的作用,在于它的通用化,如何理解这里的通用化?
Chris Lattner:如果想要获得与 FasterTransformer 相同或更好的结果,但使用的是其他通用架构(这里指非Transformer架构),那么通过编译器,就能获得两全其美的结果,可以在研究的同时获得同样优秀的性能,也就是说,在编译器层面实现优化,可以相当于一个 "AI引擎",并且在未来协助LLM架构的转变。
目前Mojo很火,它和Python生态兼容,但 Modular 的目标,是建立一个统一的人工智能引擎。那么,站在你的角度,当前在人工智能研发领域,还有哪些问题需要解决?
Chris Lattner:如果回到 2015、2016、2017 年那段时间,人工智能的迅速发展的火热阶段,而那个时代的技术,主要是由 TensorFlow 和 PyTorch 统领,PyTorch 比 TensorFlow出现稍晚些,但它们在某些方面都是类似的设计。但是,构建和设计TensorFlow 和 PyTorch 系统的人,主要是由人工智能、微分方程、自动差分的背景组成的,他们并没有解决软硬件的边界问题。
于是就需要 Keras(注释:Keras是一个由Python编写的开源人工神经网络库,可以作为Tensorflow、Microsoft-CNTK和Theano的高阶应用程序接口,进行深度学习模型的设计、调试、评估、应用和可视化) 或 nn.Module(注释:nn.Module 是PyTorch 特有的概念,也是将经常使用的一个类 )这样的存在。
这些东西的底层,其实就是算子,如何实现卷积、矩阵乘法、约简算法和逐元素运算?就需要使用CUDA和英特尔MKL(英特尔数学核心函数库)这类的,之后,在这些基础上继续构建。
刚开始这种模式是可以的,但问题也同样存在,最初的算子是很少的,但是,只要推出一种新硬件,哪怕只是英特尔随便推出一个CPU新变种,都会让计算复杂度不断上升,如今,TensorFlow和PyTorch拥有成千上万个算子,每个都被称为kernel,所有的kernel都需要由人来手动进行编写。
(注释:芯片行业中所说的IP,一般也称为IP核。IP核是指芯片中具有独立功能的电路模块的成熟设计。该电路模块设计可以应用在包含该电路模块的其他芯片设计项目中,从而减少设计工作量,缩短设计周期,提高芯片设计的成功率。该电路模块的成熟设计凝聚着设计者的智慧,体现了设计者的知识产权,因此,芯片行业就用IP核来表示这种电路模块的成熟设计。IP核也可以理解为芯片设计的中间构件)
也就是说,一旦新硬件推出,你就必须重新写上千个Kernel,于是进入硬件的门槛就会越来越高,并且,这种现状也给科研制造了很多困难,比如说,一名研究员,很少能知道这些kernel是如何工作的。
(注释:因为kernel的开发很多时候是特定硬件平台的,即便是nvidia也不是都通用,更别说FPGA或者DPU,自定义算子是扩展硬件平台软件计算能力的主要渠道)
大家应该也知道,现在很多人在编写CUDA Kernel(注释:Kernel: 在GPU上由CUDA运行的函数的名字),但这里的工程师的技能画像,和能够创新模型架构的技能完全不同。于是,很多人工智能系统就面临这样的挑战:找不到能编写 Kernel的技术专家。
(注释:使用GPU 进行计算的时候,所有计算流程都可以封装成一个 GPU 的 Kernel,放到 GPU 上执行,并且是顺序性的。传统的算子库为了通用性,会把算子设计的非常基本,因此数量也非常多)
关于谷歌的TPU
我在谷歌的时候参与过谷歌的TPU项目,当时,作为TPU团队团队面临的挑战包括,市面上有数千种不同的Kernel,如何推出一种新颖的硬件?当时,很多同事也提到过,能不能使用编译器来完成这件事。因此,与其手写数千个Kernel,重新编写所有这些算子,像英特尔或NVIDIA那样完全搞一套自己的生态,编译器可以比人工更具弹性,因为编译器可以允许我们以不同的方式混搭Kernel,还可以优化很多性能。
编译器能以通用化的方式,实现这一点,而如果我们用传统的手写Kernel,出来的一定是人们自己认为有意思的Kernel的固定排列,而不是研究人员想要的新东西。于是,谷歌的XLA(前文有解释Accelerated Linear Algebra:加速线性代数) 就此诞生。XLA可以持大规模的exaflop级计算机,但是问题又来了,XLA的出现是为了支持谷歌的TPU。
而构建编译器真的很难,且还存在可扩展性问题,目前,必须雇用编译器工程师才能完成很多机器学习的工程项目,而懂机器学习和各种相关知识的编译器工程师就更少了。除此之外,XLA 是不可扩展的,它只适配于TPU。
关于深度学习和可编程性
如果我们回头再看NVIDIA的CUDA和深度学习的发展历程,比如AlexNet的诞生和深度学习的发展,多人都认为 AlexNet 的诞生是数据、ImageNet +计算、GPU 的力量结合在一起的结果。
(注释:2012 年,深度学习三巨头之一、图灵奖得主 Geoffrey Hinton 的学生 Alex Krizhevsky 和ilya提出了 AlexNet,并在当年度的 ILSVRC以显著的优势获得当届冠军,成绩远超第二名。这一成绩引起了学界和业界的极大关注,计算机视觉也开始逐渐进入深度学习主导的时代)
但很多人忘记了"可编程性”的重要性。
因为正是CUDA ,让研究人员能够发明出以前不存在的卷积内核,那时还没有 TensorFlow。实际上,是数据、计算和可编程性之间的的结合,使得新颖的研究开启了深度学习系统的整个浪潮。
因此,从过去的事情和历史中学习,是非常重要的。那么,如何迈出下一步?在这项技术方面,我们如何进入下一个时代,让大家能够从人类惊人的算法创新和想法中获益?如何从编译器中获益?如何利用编译器的规模和通用性,从而解决新问题?最重要的是,如何从可编程性中获益?这就是,我们在做的Modular——人工智能引擎。
关于人工智能的未来
如何看待人工智能发展的未来?你认为不同画像或方向的团队会有更多的合作吗?你想要做的目标之一,是不是降低那些非编译器专家应用编译器的难度?
Chris Lattner:人类非常了不起,但没人可以把所有东西都装进自己脑袋里,不同种类、特长的人在一起工作,就能做出比所有人都伟大的东西,举个例子,我有一定能力,但我基本不记得任何微分方程,对吧?所以下一个LLM架构的发明者肯定不是我(笑)。
但是,如果从系统的角度考虑问题,如果我能让这些人一起贡献,协作,并且了解这些东西是如何工作的,就会有出现突破。如何促进发明?如何让更多了解这个问题不同部分的人,真正开展合作?因此,Mojo和引擎的探索,就是努力消除问题的复杂性。因为目前有很多已经构建好的系统,只是单纯聚合在一起。
这里的解决方案,通常只是以解决问题出发,而不是从上到下设计出来的。而我认为,Modular提供了一个更简单的堆栈,能协助降低整个堆栈的复杂性,如果不重构,还遵循支离破碎的混乱历史(人工智能领域的碎片化)一旦想稍微改变一下,都会崩溃,性能会变得很糟糕,或者没法工作,这种情况是来自于底层的碎片化。
如何理解编译器:编译器和变成语言是人类合作或跨界的媒介?
Chris Lattner:我创建Modular,不是拿着锤子找钉子,也不是为创新而创新,目前对OpenAI 这样的公司来说,少数员工需要花费大量时间手动编写 CUDA 内核。但是,针对人工智能编译器的优化,可以用编译器提高软件协作,扩大拥有不同技能和知识的人员的能力。
编译器的最终形态,是希望能让用户不需要对硬件有太多了解,可以用非常简单的汇编代码来完成任何和解决问题,编译器的真正作用是,能用更高的抽象级别来进行表达。编译器也是适当自动化通用优化的一种方式,否则,这些优化可能需要手动编程。
第一个目标是让流程尽可能简化;
第二个目标是,如果把大量的复杂性从脑子里挤出去,就能为新的复杂性腾出空间。除此之外,通过抽象化,就可以利用编译器的优势——因为编译器对细节有无限的关注,而人类不会;
更高层次的抽象,还能赋予我们很多其他能力。深度学习系统和Modular将计算提升到了图形层面,怎么解释呢,这里是说,一旦你从 for 循环这些复杂的编程语句解脱出来,变成更具有声明性的东西,就意味着在改变计算模式。很多人还没意识到这点,但我认为,这有可能实现。因为现有系统很容易让人头疼,抽象提供的很多功能,都是为了实现 Pmap 和 Vmap(注释:这俩包含自动求导和并行在内的函数转换)
而技术的提升,得益于大量层次分明和结构合理的系统和大量新颖的高性能计算类型的硬件,得益于大量已经取得的突破性进展,因此,我很希望Modular能够得到更为广泛的应用和普及,打破系列复杂性,这太美好了。
(注释:声明式编程和普通编程最大的区别就是在于多了一个时间的概念,你可以定义过去,现在和将来,而不是要保持整个执行链路的时间单向性,有了时间的概念,定义内容就可以简化,然后通过“推演”得到计算图,而不是我这写一个算子,那写一个算子,拼起来一个static的图)
能不能给Modular的人工智能引擎、人工智能框架、人工智能编译器下个定义?
Chris Lattner:大多数人在训练大模型的时候,都会用到PyTorch这类工具,在这样的场景下,很快会引入CUDA 或英特尔 MKL,我把这类统称为引擎,而提到引擎,主要指的是硬件接口,而Modular提供了一个新引擎,可以引入 TensorFlow、PyTorch 和其他,然后,用户可以以一种新的方式来驱动操作,进行硬件编程,建立在正确的抽象之上,就可以产生很酷的实现。
按照你的定义,Modular基于框架层和硬件层之间,然后我们就想知道,Modular在 A100 的petaflops(每秒钟可以进行的浮点运算次数),但是我发现,网站全部都是CPU,没看到GPU。所以我的问题是,大家都在努力让 GPU 变得更快,那么你们为什么要先让 CPU 跑起来?
Chris Lattner:从第一性原理思考,我们必须从底层开始。如何定义今天人工智能系统?很多人每天都在念叨GPU,为 GPU 争论不休,似乎一切都与 GPU 有关。但是,人工智能实际上是一个大规模、异构、并行计算问题。因此,传统人工智能,是从数据加载开始的,而GPU 不会加载数据,所以你必须进行数据加载、预处理、联网等系列工作,还包括大量的矩阵计算。
而驱动 GPU ,就一定需要CPU。当我们为Accelerator 开发软件时,会发现各种问题都存在,开发者认为重要的东西,才是他们要解决问题的重要部分。于是,大家就去基于问题构建一个系统,还得完全按照芯片的要求去设计。
从技术的角度来看,Modular就是想要构建通用的编译器,因为从通用到垂直是容易的,但XLA给我的经验是, 从专业化的东西开始再将其通用化的不可行的。
对于人工智能行业来说,训练规模与研究团队规模成正比,而推理规模与产品规模、用户群等成正比。因此,现在很多推理仍然是在 CPU 上完成的。因此,我们决定从 CPU 开始,先改进架构,而 CPU也更容易使用,而且不会买不到,等到通用架构构建完成之后,就可以继续扩展。然后我们目前也弄GPU,很快就会推出,随着时间的推移,扩展到这些不同类型的Accelerator中。
实际构建引擎的过程中存在有哪些技术挑战?
Chris Lattner:我们团队里的成员,基本接触过业界里所有编译器和相关存在,比如我参与过XLA 和 TensorFlow的研究,还有来自 PyTorch、TVM、英特尔 OpenVINO 、Onyx Runtime的成员,大家面临的挑战是,很多系统都是五到八年前设计的。那个时候的人工智能和现在不一样,不存在大语言模型。
问题在于,当你构建一个系统时,它一开始只是一堆代码,然后会变得越来越大、越来越大、越来越大。而系统发展得越快,就越难做出根本性改变。因此,我们选择从头开始重新做。
如果你还是希望能够手写Kernel,我们首先会用 C++ 制作原型,随后逐步引入mojo ,也就是说,你可以构建非常复杂的自动融合编译器,应用了所有最先进的技术,同时也超越了最先进的技术。
我们知道,用户讨厌静态形状限制( Static Shape Limitations),讨厌缺乏可编程性。例如,他们不希望只与Tensor绑定(注:Tensor实际上就是一个多维数组multidimensional array,目的是能够创造更高维度的矩阵、向量。而很多大模型都存在不规则Tensor的情况)
有没有关于Modular的设计目标?或者原则?
Chris Lattner:我不知道自己是否有一套成系统的原则,听起来有一套原则有点像拿着锤子看什么都是钉子。不过,我们要做的很多事情是释放硬件潜能,并且以一种超级易用的方式做到这点。因此,很多起始条件并不是启用新事物,更多的是要解决完成任务时的复杂问题,因此更像是设计和工程。
如果和一家 LLM 公司聊天,很容易就发现他们在 GPU 和特定内存大小的 A100 GPU 上花费了 超2 亿美元,大家都希望通过GPU(算力)获得所有的可能性,一方面,很多人希望能深入到芯片内部,释放潜力,但还有很多其他人想要更多的可移植性、通用性和抽象性。
因此,这里的挑战,就变成了如何启用和设计系统,并且在默认情况下获得抽象性,同时又不放弃所有的功能。同样,很多编译器,特别是机器学习编译器,基本只是试图覆盖空间中的一个特定点,功能不具备通用性。
还有就是我们关心用户,因为很多人沉迷于技术,却忘记了应用技术与创建技术的人的画像,是截然不同的,需要理解使用工具的开发者的想法。
这几天Modular刚发布了基于 Linux Mojo的下载使用,很快MacOS 和 Windows 版本也马上会发布,那么现在开始的六到九个月内,还会有哪些工具包和组件?
Chris Lattner:Mojo 仍然是一门年轻的语言,我们会逐步和生态一起,让它越来越成熟。我们希望围绕在 Mojo 周围,有一个大社区,来共同构建很酷的东西。为了实现这一目标,我们将逐步开源 Mojo,大家必须一起来解决很多细节问题,才能构建一个运行良好的生态,而不仅是一个烂摊子。
就像所有人都经历过的 Python 2-3 灾难一样,没有人愿意去回忆它(注释:这俩8成以上语法不兼容,而且由于历史遗留问题,很多Linux的发行版底层依赖py2,但是用户不小心要用py3,pip install xxx的东西就把系统搞崩溃了)。
问:你跟 Guido (注:荷兰工程师Guidovan Rossum,发明了Python语言)和 Python 基金会是什么样的关系?是如何相互关联的?
Chris Lattner:Guido知道 Mojo 即将推出, Guido花了很多时间和我们团队在一起,我们觉得很幸运。他偶尔会出现在 Discord mojo社区,给我出难题,真是太棒了。
我们认为,mojo是Python 家族的一员,当然,Python 家族还有很多成员,包括 PyPy 和 Cython 等等,我我们希望 Python 能够继续发展,不断添加新的内容。Mojo 也继续发展并添加新内容。
回到 30、40 年前,当时有 C 语言,然后在 1983 年出现了一个叫 C++ 的新生事物, C++ 其实就是带类的C语言(C with classes)(注释:1979年,Bjame Sgoustrup到贝尔实验室,开始把C改造成带类的语言,1983年该语言被正式命名为C++)
当时的情况是,C 和 C++ 最初是两个不同的社区,但它们之间有大量的融合、想法分享和想法交流。
当然,所有的 C 语言特性最终也都融入了 C++。所以我希望同样的事情也会发生在Mojo和Python上。
关于创业和工程团队建设
曾经有很多像你这样的创始人,有着很长的、了不起的工程师职业生涯。突然之间,就成了首席执行官。那么,你在组建团队、指导他人方面有什么心得体会?尤其当了工程师之后,现在又要兼任产品负责人、负责融资,有什么心得?
Chris Lattner:在 Modular,我和联合创始人Tim关系非常紧密,非常互补。在创业的过程中,有一个可以倾诉的对象真的非常非常重要。现在经历的,是我在谷歌和苹果担任工程负责人或没有体会过的。
当我们创办这家公司时,我们的信念是——理解痛苦。代表一个大厂,和代表创业公司出门是不一样的,当创业公司真正成立之后,我去做工程负责人,开始组建工程团队,而Tim会则负责产品和业务方面的工作,并在没有大厂光环的情况下和不同的公司(客户)交流。比如,你目前的痛点是什么?
目前在做什么?面临的挑战是什么?我们能帮上什么忙?你们对我们做的事情有何看法?作为Modular来说,我们所面临的挑战是,我们要打造的东西真的是一个超难的、并且非常抽象的技术问题。
要解决这些难度如此之高的问题,需要从所有大科技公司中聘请成本非常高的技术专家,因此,我必须融到大量资金,很好地激励员工,给他们发工资,让员工感到舒适。
我们直接面对客户,我们看到了AI智能领域存在的客户的痛苦,构建和部署很多东西真的是一团乱麻,大家被太多无效的东西裹挟。所以,我们的愿景,就是让由Modular去统一所有这些东西。
但问题又来了,在开发产品的同时,产品也在不断变化,需求会随着时间不断变化。因此,与我们合作的团队最终的情况是,复杂度非常高,大家为不同的特殊情况开发了很多不同的混乱系统。
作为工程领导者的经验:有大量组建团队和招聘工程师的经验。在工程管理方面有什么心得或建议?
Chris Lattner:我的工作就是帮助团队获胜,必须定义什么是赢,就要给人们一个清晰的愿景,一个明确的目标,让大家保持一致,当你有周围有一大群非常优秀的人,都想成为英雄时,明确的目标就会非常重要。势能叠加,会迅速取得巨大进步,而反之,动力就会抵消。
在我们内部,我经常会亲自帮助构建初始基础工程,向团队展示如何落地非常重要,这也是我们的文化。在工程团队中,对我来说最重要的一点就是落地速度,如果等上24 小时或三周才能运行 CI,那么一切都会慢下来。
在招聘时和员工不断发展的过程中,你也要确定,员工擅长什么,对吗?我真的相信,如果你有一个非常优秀、非常有激情的,团队成员,而你又把他们和他们真正想做的事情结合在一起,那么,他们就具备超能力。
因此,很多时候,我们要确保人们在解决正确的问题。这样,他们就能成长,能做事,能推动,能自主决策。但很多时候,人们会非常专注于产品,或者有的特别擅长做生意,专注于客户和客户遇到的问题。但如果没有团队,就无法解决和打造产品。
我很喜欢Tim,因为他真的很擅长我不太擅长的领域,大家都在互相学习。
关于ChatGPT和人工智能
ChatGPT的爆发超级有趣,对于像我们这样长期关注人工智能的人来说,ChatGPT意味着一种用户界面创新,并且让人们认识到了人工智能的力量。回过头来看,我认为这让人工智能在公众意识中的地位提高了好几年。
人工智能领域最有趣的未解之谜是什么?
ChrisLattner:我认为人工智能现在正处于青春期。有很多聪明人对AI是什么有不同的看法,对吧?有些人认为一切都应该是端到端的神经网络,软件应该消失,我认为待解决的问题是,训练算法和智能设计算法之间的平衡到底是怎样的?我个人不认为这是全是一种或全是另一种,如果你想构建一个cat detector,那么 CNN 确实是一个很好的方法。如果你想编写一个引导加载程序或操作系统,那么 用for 循环实现也很好。但随着时间的推移,这些东西会在哪些方面逐步淘汰?我们又该如何让应用开发者能够更一致思考这些呈现?
我们对未来下的赌注是:人工智能将作为一种软件开发方法,最终会成为人们思考如何构建应用程序工具集的一部分。不仅仅是 iPhone 应用或类似的形态,还包括整个云服务、数据管道,最终迭代整个用户产品的构建,当然,我们目前也还在探索的道路上。
*感谢技术生活进化论所有朋友们对笔者多年来一如既往的支持,感谢ChaosAI
*感谢Dakai、AsyncGreed、张博、毛利、Ethan、Mew在专业知识上给予的帮助
参考文献:
1.https://www.latent.space/p/modular
2.参考资料:芯片行业所说的IP是个什么东西?-芯论语-天高云淡Andi863
3.Chris Lattner's Homepage (nondot.org)
4.nn.functional和nn.Module-梁云1991算法美食屋2020-07-10 21:47
5.参考资料:简书-Aug 12, 2018-深入浅出让你理解什么是LLVM
查看更多





